导出SQL运行结果的方法总结
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId"; private static final String accessKey = "userAccessKey"; private static final String endPoint = "http://service.odps.aliyun.com/api"; private static final String project = "userProject"; private static final String sql = "userSQL"; private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字 private static final Odps odps = getOdps(); public static void main(String[] args) { System.out.println(table); runSql(); tunnel(); } /* * 把SQLTask的结果下载过来 * */ private static void tunnel() { TableTunnel tunnel = new TableTunnel(odps); try { DownloadSession downloadSession = tunnel.createDownloadSession( project, table); System.out.println("Session Status is : " + downloadSession.getStatus().toString()); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema()); } recordReader.close(); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } /* * 保存这条数据 * 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。 * */ private static void consumeRecord(Record record, TableSchema schema) { System.out.println(record.getString("username")+","+record.getBigint("cnt")); } /* * 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载 * 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间 * */ private static void runSql() { Instance i; StringBuilder sb = new StringBuilder("Create Table ").append(table) .append(" lifecycle 1 as ").append(sql); try { System.out.println(sb.toString()); i = SQLTask.run(getOdps(), sb.toString()); i.waitForSuccess(); } catch (OdpsException e) { e.printStackTrace(); } } /* * 初始化MaxCompute(原ODPS)的连接信息 * */ private static Odps getOdps() { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(endPoint); odps.setDefaultProject(project); return odps; }有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
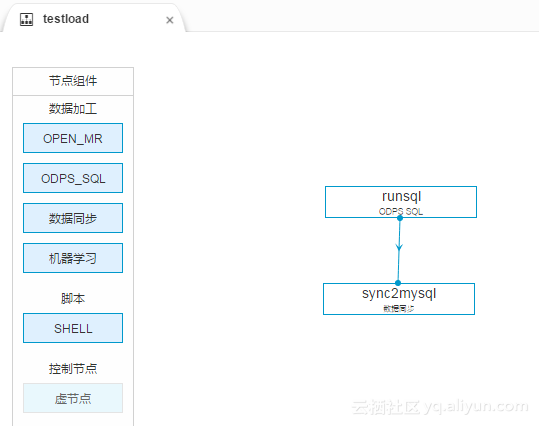
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
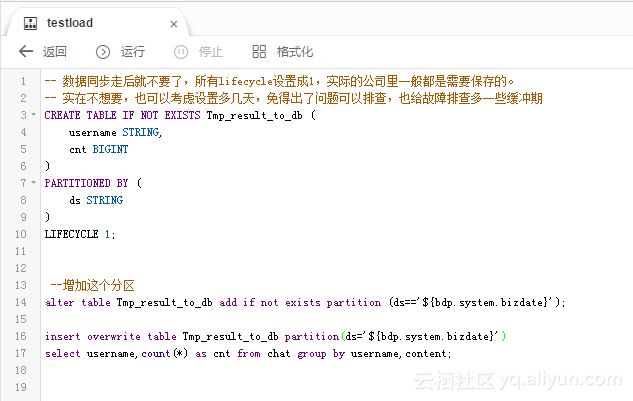
里面配置的SQL作业和同步作业的配置如图:
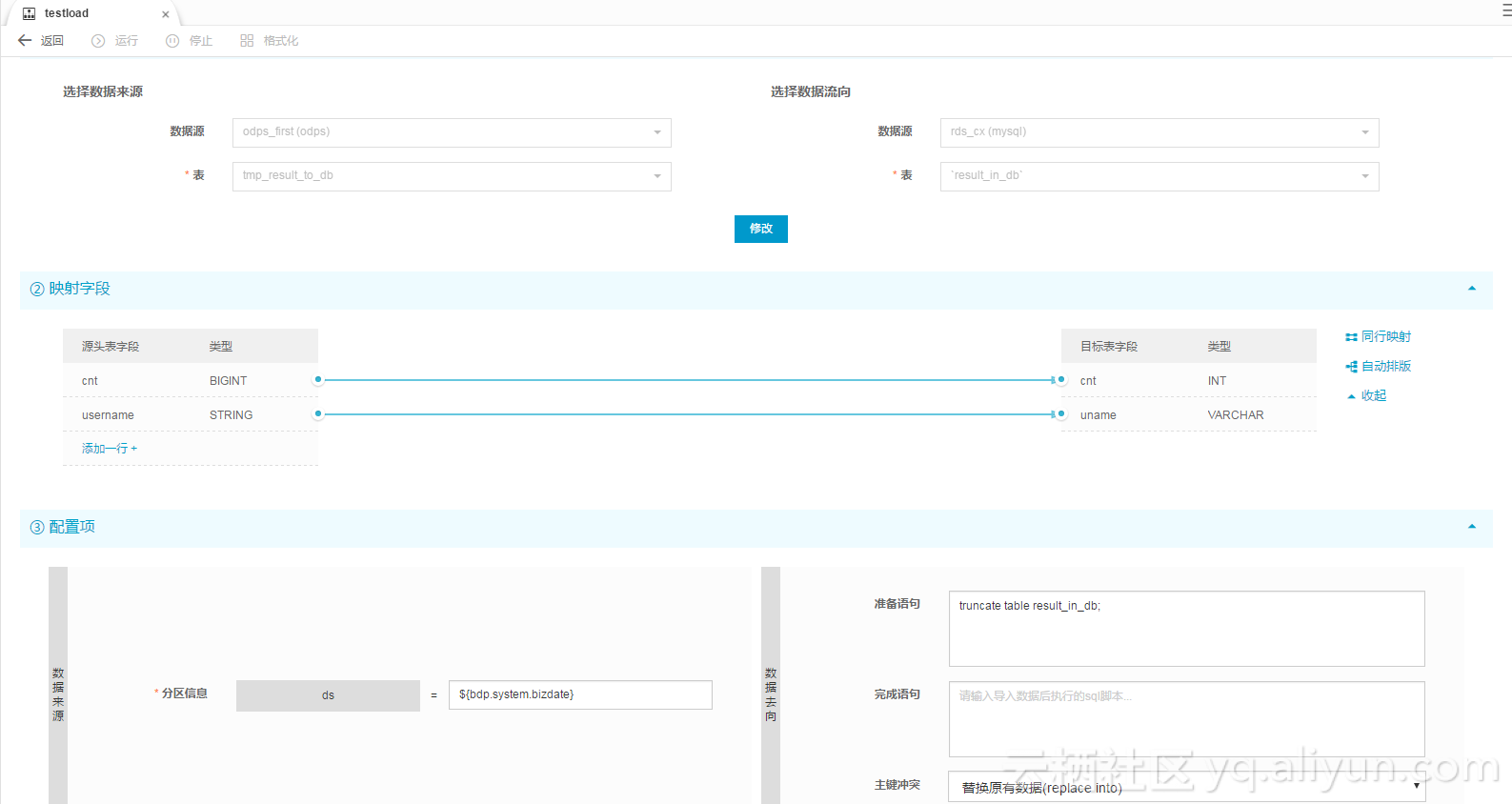
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
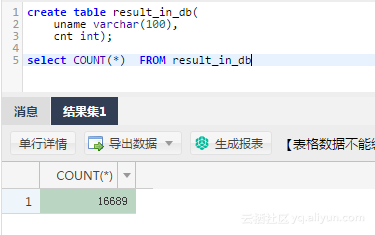
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34任务结束时刻 : 2016-12-17 23:43:46任务总计耗时 : 11s任务平均流量 : 31.36KB/s记录写入速度 : 1668rec/s读出记录总数 : 16689读写失败总数 : 0到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
小编还为您整理了以下内容,可能对您也有帮助:
SQL中,我想把SQL查询分析器查询出来的结果,导出到EXCEL表格,求各位大侠指点。
比较常用的方法:
1、使用Sql的导出功能(比较专业,不会出错)
在数据库上右击 【任务】--【导出数据】--选择源--选择目标(类型选择EXCEL)--选择 查询结果导出
2、结果直接保存(比较简单,但是全是数字的字符串可能会被自动转换成数字)
在查询分析器里面执行SQL语句后选择查询的结果然后右键 【将结果另存为】--选择保存类型【*.csv】
3、全选你要保存的所有行,然后右击,然后选择copy to excel就OK
导出sql数据库数据的方法有几种方式
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId"; private static final String accessKey = "userAccessKey"; private static final String endPoint = "http://service.odps.aliyun.com/api"; private static final String project = "userProject"; private static final String sql = "userSQL"; private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字 private static final Odps odps = getOdps(); public static void main(String[] args) { System.out.println(table); runSql(); tunnel(); } /* * 把SQLTask的结果下载过来 * */ private static void tunnel() { TableTunnel tunnel = new TableTunnel(odps); try { DownloadSession downloadSession = tunnel.createDownloadSession( project, table); System.out.println("Session Status is : " + downloadSession.getStatus().toString()); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema()); } recordReader.close(); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } /* * 保存这条数据 * 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。 * */ private static void consumeRecord(Record record, TableSchema schema) { System.out.println(record.getString("username")+","+record.getBigint("cnt")); } /* * 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载 * 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间 * */ private static void runSql() { Instance i; StringBuilder sb = new StringBuilder("Create Table ").append(table) .append(" lifecycle 1 as ").append(sql); try { System.out.println(sb.toString()); i = SQLTask.run(getOdps(), sb.toString()); i.waitForSuccess(); } catch (OdpsException e) { e.printStackTrace(); } } /* * 初始化MaxCompute(原ODPS)的连接信息 * */ private static Odps getOdps() { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(endPoint); odps.setDefaultProject(project); return odps; }工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
里面配置的SQL作业和同步作业的配置如图:
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34任务结束时刻 : 2016-12-17 23:43:46任务总计耗时 : 11s任务平均流量 : 31.36KB/s记录写入速度 : 1668rec/s读出记录总数 : 16689读写失败总数 : 0到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
导出sql数据库数据的方法有几种方式
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId"; private static final String accessKey = "userAccessKey"; private static final String endPoint = "http://service.odps.aliyun.com/api"; private static final String project = "userProject"; private static final String sql = "userSQL"; private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字 private static final Odps odps = getOdps(); public static void main(String[] args) { System.out.println(table); runSql(); tunnel(); } /* * 把SQLTask的结果下载过来 * */ private static void tunnel() { TableTunnel tunnel = new TableTunnel(odps); try { DownloadSession downloadSession = tunnel.createDownloadSession( project, table); System.out.println("Session Status is : " + downloadSession.getStatus().toString()); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema()); } recordReader.close(); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } /* * 保存这条数据 * 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。 * */ private static void consumeRecord(Record record, TableSchema schema) { System.out.println(record.getString("username")+","+record.getBigint("cnt")); } /* * 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载 * 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间 * */ private static void runSql() { Instance i; StringBuilder sb = new StringBuilder("Create Table ").append(table) .append(" lifecycle 1 as ").append(sql); try { System.out.println(sb.toString()); i = SQLTask.run(getOdps(), sb.toString()); i.waitForSuccess(); } catch (OdpsException e) { e.printStackTrace(); } } /* * 初始化MaxCompute(原ODPS)的连接信息 * */ private static Odps getOdps() { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(endPoint); odps.setDefaultProject(project); return odps; }工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
里面配置的SQL作业和同步作业的配置如图:
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34任务结束时刻 : 2016-12-17 23:43:46任务总计耗时 : 11s任务平均流量 : 31.36KB/s记录写入速度 : 1668rec/s读出记录总数 : 16689读写失败总数 : 0到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
sql数据库如何导出?
1、打开SQL Server,找到需要导出的数据库。
2、在需要导出的数据库上右击,选择任务选项中的导出数据选项。
3、SQL Server导入和导出向导窗口中,单击下一步按钮。
4、选择数据源对话框中,选择数据源选项中的Microsoft OLE DB Provider for SQL Server选项。
5、选择使用SQL Server身份验证,输入用户名和密码,选择要导出的数据库,单击下一步。
6、选择目标对话框中,选择目标选项中的Microsoft OLE DB Provider for SQL Server选项。
7、选择使用SQL Server身份验证,输入用户名和密码,单击新建按钮。
8、出现的创建数据库窗口中,在名称处输入一个导出数据库的名字,本例为NewData。
9、可以看到在数据库选项中,多出了一个NewData的名称,单击下一步。
10、指定复制或查询对话框中,选择复制一个或多个表或视图的数据选项,单击下一步。
11、选择源表和源视图对话框中,选择自己要导出的表和视图。
12、运行包对话框中,单击完成按钮。
13、数据就成功导出了。
怎么输出sql的查询结果?
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId"; private static final String accessKey = "userAccessKey"; private static final String endPoint = "http://service.odps.aliyun.com/api"; private static final String project = "userProject"; private static final String sql = "userSQL"; private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字 private static final Odps odps = getOdps(); public static void main(String[] args) { System.out.println(table); runSql(); tunnel(); } /* * 把SQLTask的结果下载过来 * */ private static void tunnel() { TableTunnel tunnel = new TableTunnel(odps); try { DownloadSession downloadSession = tunnel.createDownloadSession( project, table); System.out.println("Session Status is : " + downloadSession.getStatus().toString()); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema()); } recordReader.close(); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } /* * 保存这条数据 * 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。 * */ private static void consumeRecord(Record record, TableSchema schema) { System.out.println(record.getString("username")+","+record.getBigint("cnt")); } /* * 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载 * 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间 * */ private static void runSql() { Instance i; StringBuilder sb = new StringBuilder("Create Table ").append(table) .append(" lifecycle 1 as ").append(sql); try { System.out.println(sb.toString()); i = SQLTask.run(getOdps(), sb.toString()); i.waitForSuccess(); } catch (OdpsException e) { e.printStackTrace(); } } /* * 初始化MaxCompute(原ODPS)的连接信息 * */ private static Odps getOdps() { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(endPoint); odps.setDefaultProject(project); return odps; }工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
里面配置的SQL作业和同步作业的配置如图:
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34任务结束时刻 : 2016-12-17 23:43:46任务总计耗时 : 11s任务平均流量 : 31.36KB/s记录写入速度 : 1668rec/s读出记录总数 : 16689读写失败总数 : 0到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
怎么输出sql的查询结果?
SQLTask+Tunnel
可以看到,SQLTask不能处理超过1万条记录,但是Tunnel刚好可以,两者存在互补。所以可以基于两者实现数据的导出。以下用一个代码的例子来实现:
private static final String accessId = "userAccessId"; private static final String accessKey = "userAccessKey"; private static final String endPoint = "http://service.odps.aliyun.com/api"; private static final String project = "userProject"; private static final String sql = "userSQL"; private static final String table = "Tmp_" + UUID.randomUUID().toString().replace("-", "_");//其实也就是随便找了个随机字符串作为临时表的名字 private static final Odps odps = getOdps(); public static void main(String[] args) { System.out.println(table); runSql(); tunnel(); } /* * 把SQLTask的结果下载过来 * */ private static void tunnel() { TableTunnel tunnel = new TableTunnel(odps); try { DownloadSession downloadSession = tunnel.createDownloadSession( project, table); System.out.println("Session Status is : " + downloadSession.getStatus().toString()); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema()); } recordReader.close(); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } /* * 保存这条数据 * 数据量少的话直接打印后拷贝走也是一种取巧的方法。实际场景可以用Java.io写到本地文件,或者写到远端数据等各种目标保存起来。 * */ private static void consumeRecord(Record record, TableSchema schema) { System.out.println(record.getString("username")+","+record.getBigint("cnt")); } /* * 运行SQL,把查询结果保存成临时表,方便后面用Tunnel下载 * 这里保存数据的lifecycle为1天,所以哪怕删除步骤出了问题,也不会太浪费存储空间 * */ private static void runSql() { Instance i; StringBuilder sb = new StringBuilder("Create Table ").append(table) .append(" lifecycle 1 as ").append(sql); try { System.out.println(sb.toString()); i = SQLTask.run(getOdps(), sb.toString()); i.waitForSuccess(); } catch (OdpsException e) { e.printStackTrace(); } } /* * 初始化MaxCompute(原ODPS)的连接信息 * */ private static Odps getOdps() { Account account = new AliyunAccount(accessId, accessKey); Odps odps = new Odps(account); odps.setEndpoint(endPoint); odps.setDefaultProject(project); return odps; }工具实现
有时候我们希望把数据导出后用文本文件来保存,但是有时候会希望保存到数据库或者其他的别的什么地方。为了避免重复造轮子,阿里开源了工具DataX。通过配置配置文件,可以很方便的导出MaxCompute里的数据到目标数据源。
工具的安装自不必多说,关于插件的配置,可以看到有分为Reader和Writer,还有一个用来配置整个任务的诸如速度并发限制的Setting。通过配置Reader和Writer,可以很方便地适配不同的数据源。
云产品
细心的你可能已经发现,这个解掉了数据下载后保存的问题,但是还是没解决数据的生成以及两个步骤之间的调度依赖的问题。
这里隆重为大家介绍阿里云大数据开发套件这个产品,我们可以在里面运行SQL、配置任务同步(基于dataX实现),还可以设置自动周期性运行还有多任务之间的依赖,彻底解决了前面的所有烦恼。
我们先创建一个工作流,里面可以有一个SQL节点和一个数据同步节点。如图
里面配置的SQL作业和同步作业的配置如图:
注意SQL这里的创建表我先执行了一下再去配置同步(否则表都没有,同步任务没办法配置)
运行测试后,可以看到日志里显示
2016-12-17 23:43:46.394 [job-15598025] INFO JobContainer - 任务启动时刻 : 2016-12-17 23:43:34任务结束时刻 : 2016-12-17 23:43:46任务总计耗时 : 11s任务平均流量 : 31.36KB/s记录写入速度 : 1668rec/s读出记录总数 : 16689读写失败总数 : 0到mysql里查一下,数据也进去了。
总结
阅读原文请点击
导出SQL运行结果的方法总结
标签:container 参考 工作流 product 存在 dom idt 开发 put
sql server怎么快速导出查询到的数据
第一种方法:
1、登陆sql server2012。
2、首先要选中要导出的数据,点击表格左上角,选中整个表格的数据——右击左上角,在菜单中选择“将结果另存为”——填写文件名——保存文件。
可以在桌面上看到该文件,已经被识别成一个excel了。
双击打开,可以看到数据内容。
还有一种方法
除了保存成csv文件外,还可以直接复制。在右键菜单中选择“连同标题一起复制”
打开记事本,粘贴内容,可以看到数据内容。最上面那行是数据标题。
如何将SQL server 2008 里的查询结果导出到 Excel 表内?
1、首先打开SQL server 2008 应用程序,进入到程序操作页面中,选择需要编辑的表。
2、然后在弹出来的窗口中查询数据,之后就可以看到想要导出来的数据了。
3、然后鼠标右键单击该页面空白的地方,选择打开“将结果另存为”。
4、然后在跳出来的窗口中,点击打开“保存类型”,选择“CSV”格式,回车确定。
5、然后点击打开另存为的文件,就可以在Excel表格中打开了。